LSM Store and Shards
In last post. I explained how Updates are chained in linked-list and organized into log files. Today we will discus shards and better compaction.
All articles from ‘LSM Store’ series are under LSM tag.
Dictionary
Journal - small set of most recent Updates, is durably stored on disk
Update - is single atomic modification made on store. It inserts or deletes multiple keys. Synonym is Commit.
Log - is a sequence of Updates. Each Update links to older Update, that creates Log. (or Linked-List of Updates)
Shard - Set of keys within single interval. All keys in Shard are between its lower and upper bound. Shard file is single log of Updates. It is organized the same way as log in previous chapter.
Durable - data written to disk in way that survives system crash. File sync is called to flush disk cache.
LSM Tree and scalability
Store described in last chapter used single Log (linked-list) to store all data.
Log uses binary search to find keys (within single Update) with time complexity O(log N), where N is number of keys in single update.
Each modification adds new entry to Log (Update). So with multiple Updates, the worst time needed to find keys is O(U * log N), where U is number of Updates (linked-list size).
U grows over time and performance decreases linearly with number of updates. To reduce U, linked-list is periodically compacted, in this case all Updates are merged into single Update. U is 1 and older Updates are discarded.
Time required for compaction is O(N*log(U)). Compaction performance decreases linearly with number of keys.
And this creates scalability problem. Naive single-log approach is trapped between two rocks: On one side time needed to find a key increases linearly with number of updates. On other side time needed for compaction increases linearly with number of keys.
For that reason, LSM Tree with single log-file design is not practical for use. One one side you have great read performance, but store can not be modified. On other side you have store with great write performance, but slow reads.
There are two solutions for this scalability problem. First one is multi-level merge used in RocksDB (or Cassandra’s SSTables). Second solution is Journal with Shards, used in IODB.
RocksDB approach
Internals of RocksDB LSM-Trees are well explained at this video, explanation starts at time mark.
In short: Store is organized into levels. Level 0 has most recent changes and is smallest, Level N has oldest changes and is largest. Compaction moves data from younger to older levels. Each Level contains multiple files. To find a key you traverse levels from newest to oldest, at each level you search all files for given key.
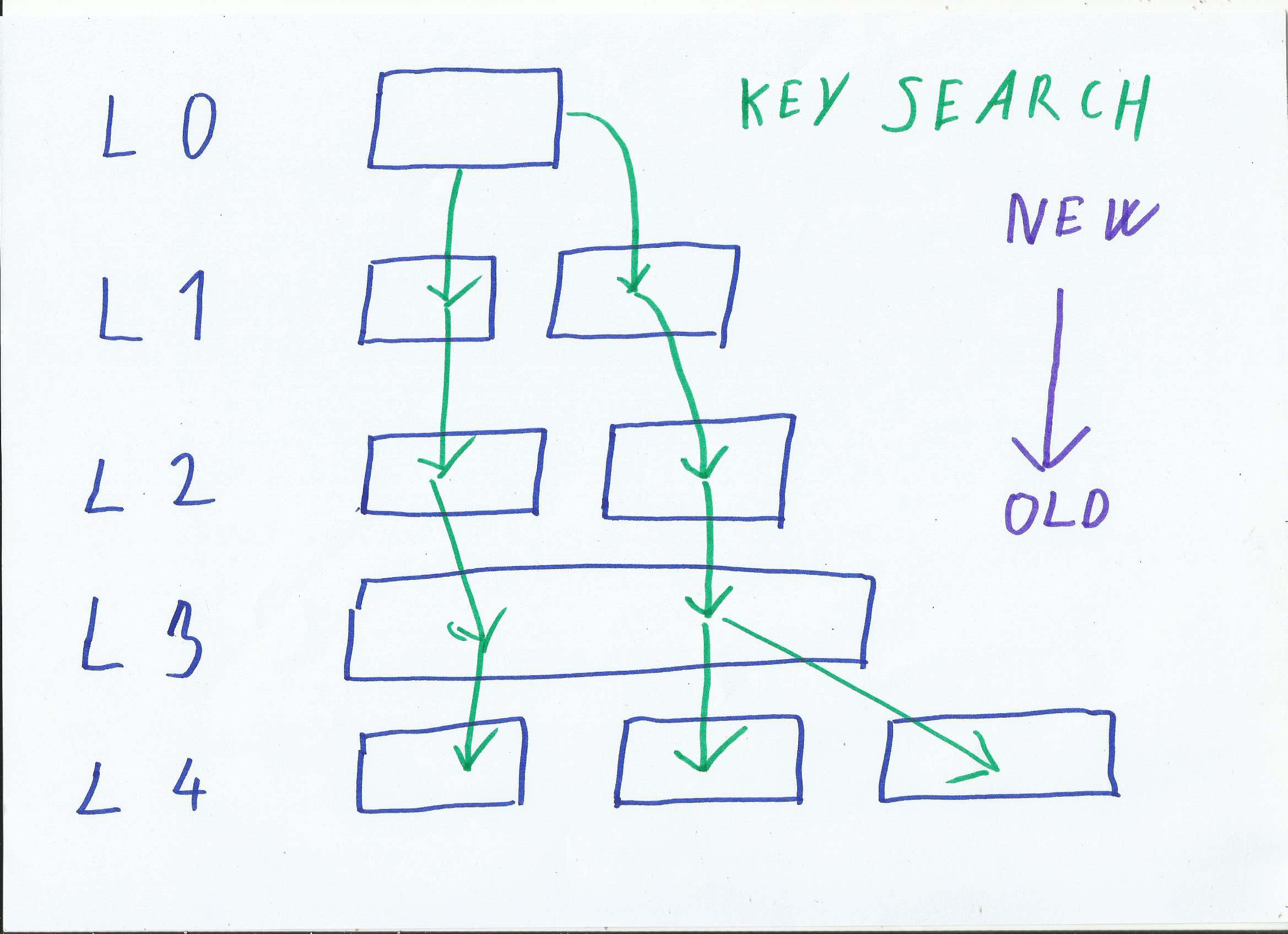 RocksDB multilevel store; it also shows key search in green, all files have to be traversed to find a key
RocksDB multilevel store; it also shows key search in green, all files have to be traversed to find a key
RocksBD multi-level design has some problems:
First there is the memory consumption. Entire Level-0 and memtable (uncommited data) is held in memory. Each file also needs in-memory bloom filter (compressed bitmap), to minimize time needed to search for key. RocksDB memory usage is not constant, but grows linearly with number of stored keys.
Secondly key-search is very inefficient. In worst case you need to binary search all files in store. It is only manageable thanks to in-memory bloom filters, at the cost of high memory consumption.
Another problem is compaction. Large number of overlapping files at multiple levels is not easy to deal with. RocksDB has two compaction strategies with many settings and trade-offs. Compaction should be simpler.
Some files in RocksDB can be a quite large, and it takes long time to compact large file. And there is space overhead, large files need extra space for compaction. Worsts case is full compaction, when store size temporary doubles. If there is no free space, compaction can not progress.
Long running tasks are also harder to manage. When task is terminated, its progress is lost. Imagine compaction task takes several hours, and you have to restart more often. Compaction will newer progress in such environment.
In IODB design we limit maximal file size. This way each tasks finishes within a few seconds (or minutes) and needs only a few extra MBs. Smaller tasks are easier to manage, more efficient on system resources, and much easier to pause and terminate.
And finally RocksDB does not support rollbacks that well. It has snapshots and backups, but there is no native support for branching out from old rollbacks.
Shards
IODB and StoreLSM design differs from RocksDB. RocksDB slices data into levels, most recent updates are in smallest level, and are propagated to lower levels by compaction process.
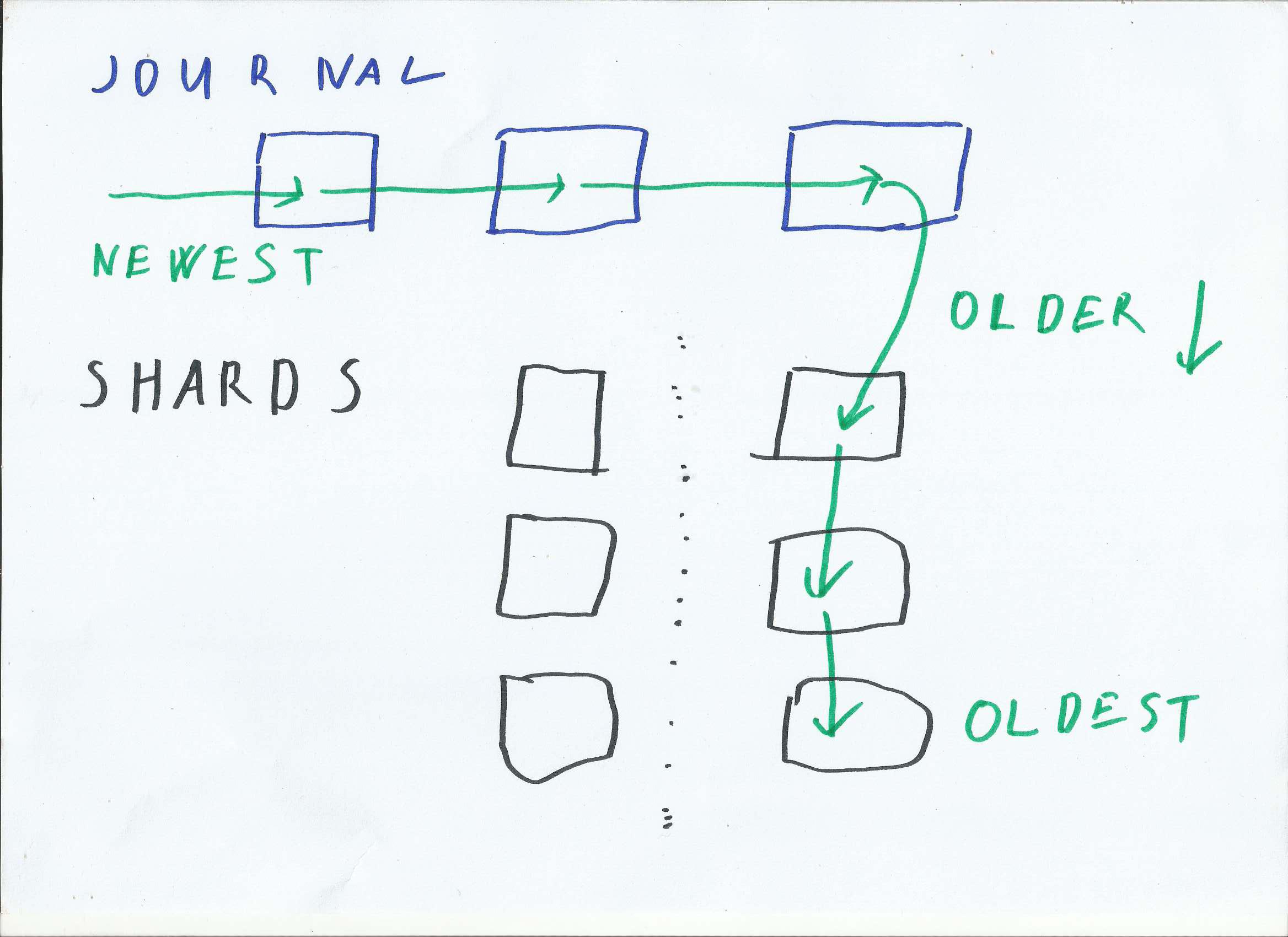 Age of data in IODB
Age of data in IODB
Our design first puts all Updates into Journal. Once Journal is sufficiently large, its content is sliced into intervals (Shards). Image above illustrates what happens with data after insert. Most recent data are placed into Journal. Older data are propagated into shards.
Each Shard is a separate log (linked-list of updates), and is updated and compacted independently. Using smaller intervals ensures that single compaction tasks is never too big. To find a key, only a small Shard needs to be traversed.
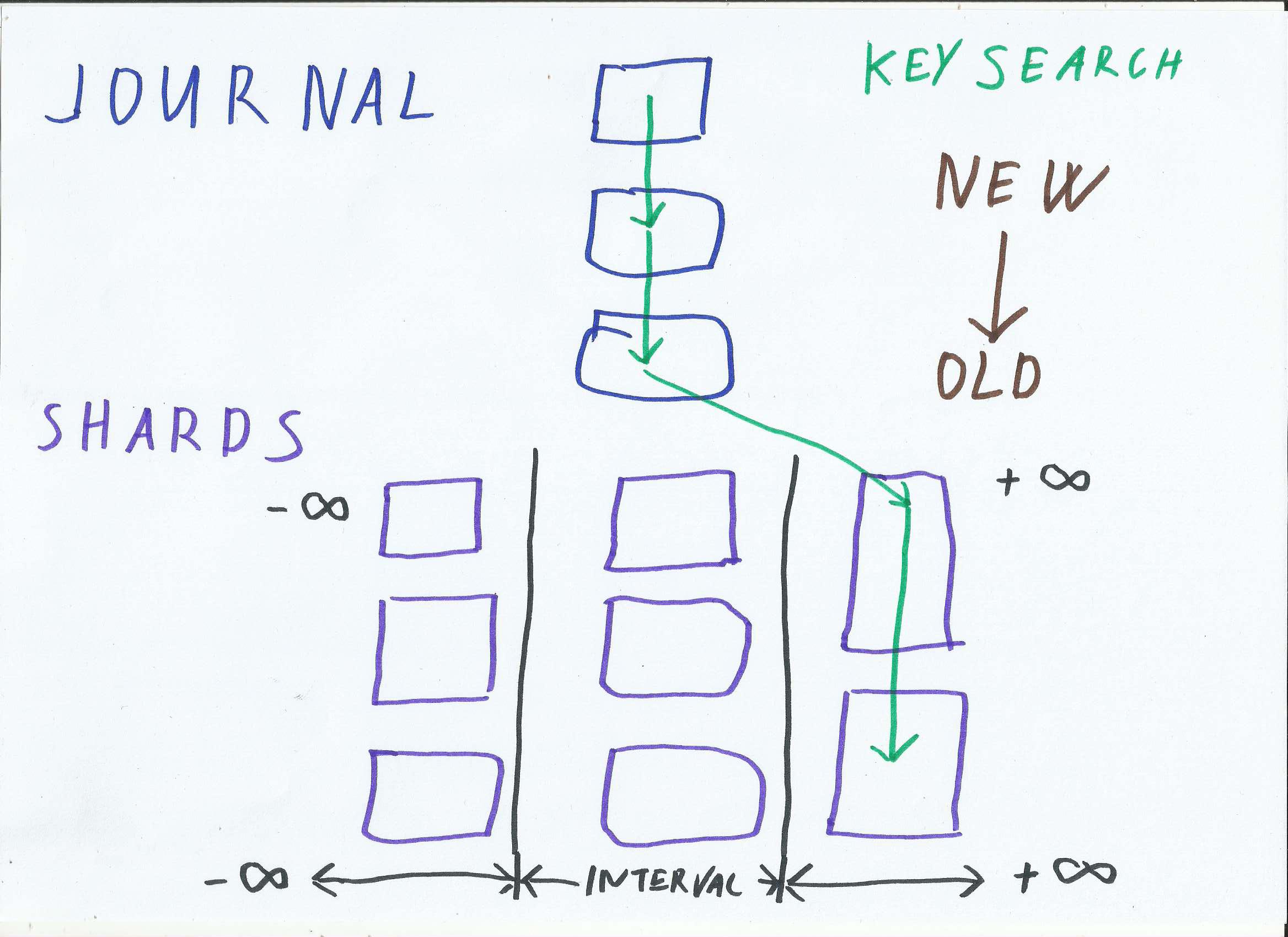 Illustration of key search (green). In RocksDB all files needs to be searched to find a key. In our design only small portion of data (single Shard) is traversed to find a key.
Illustration of key search (green). In RocksDB all files needs to be searched to find a key. In our design only small portion of data (single Shard) is traversed to find a key.
Data flow in IODB
In IODB all modifications are grouped into Updates.
Updates are durably written into Journal
There is a Sharding Task running in background thread
Every N seconds (or N updates) Journal content becomes large enough, the Sharding Task takes Journal content and distributes it between Shards
Data written into Shards are durable, so the Journal can be discarded, once data are written into Shards.
There is also Shard Compaction Task running in background, it chooses Shard with most unmerged Updates, and runs compaction on this Shard.
 Sharding - moving data from Journal to Shards, Journal is deleted once data are written to Shards.
Sharding - moving data from Journal to Shards, Journal is deleted once data are written to Shards.
Key Search
Key Search needs to find most recent version of key, in other words: it needs to find most recent Update when key was inserted, modified or deleted.
Journal and Shard are in practice logs. They are searched similar way as
single linked-list of Updates from previous chapter.
Most recent Updates are in Journal. So in first step Journal is searched. IODB caches Journal content in memory, so this requires single lookup.
Older updates are stored in Shards. IODB compares key with Shard boundaries to find correct Shard for a key.
After Shard is selected, it is traversed the same way as single log. Binary search is performed on each Update, until key is found or end of linked-list is reached (not found).
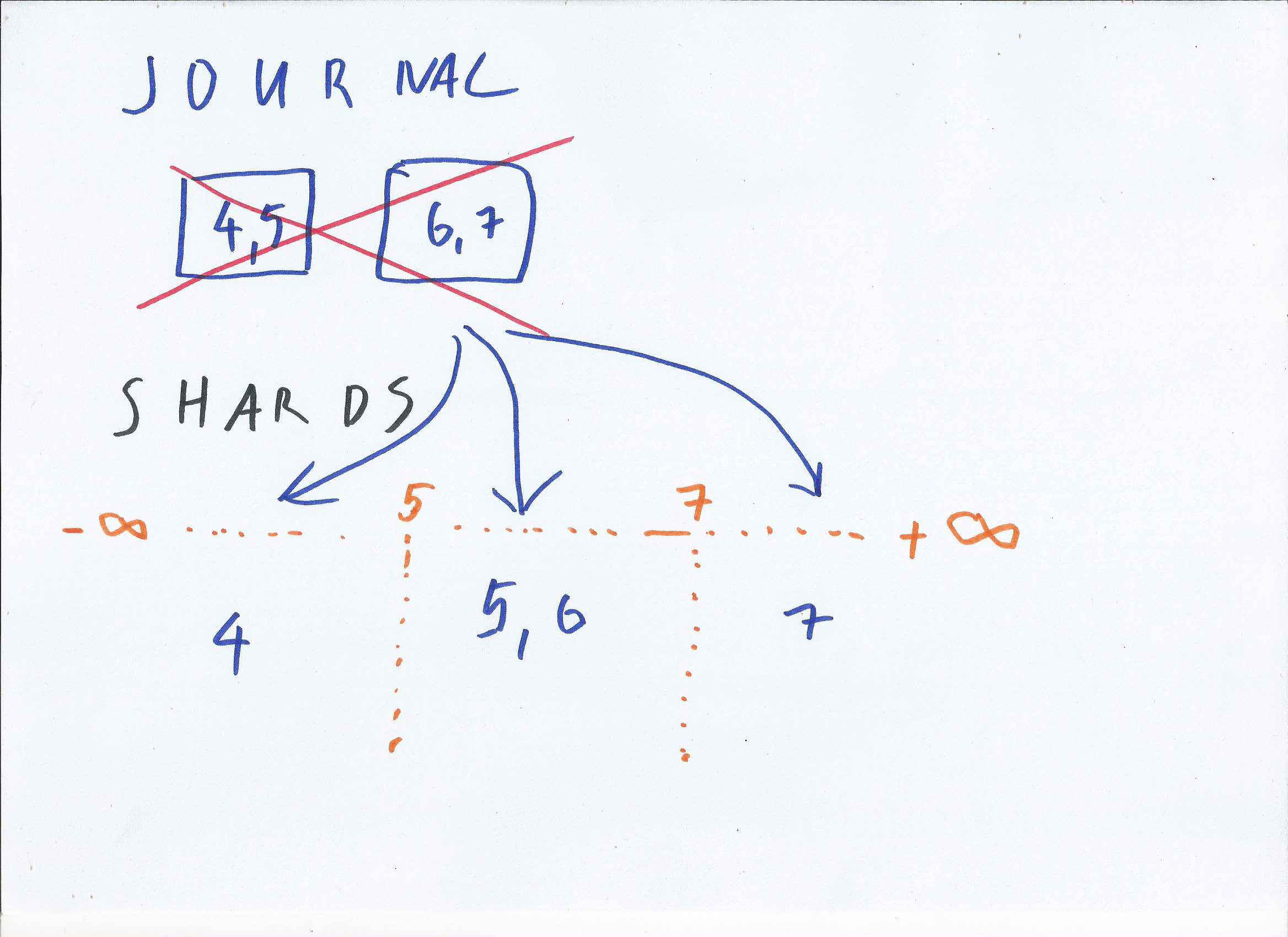
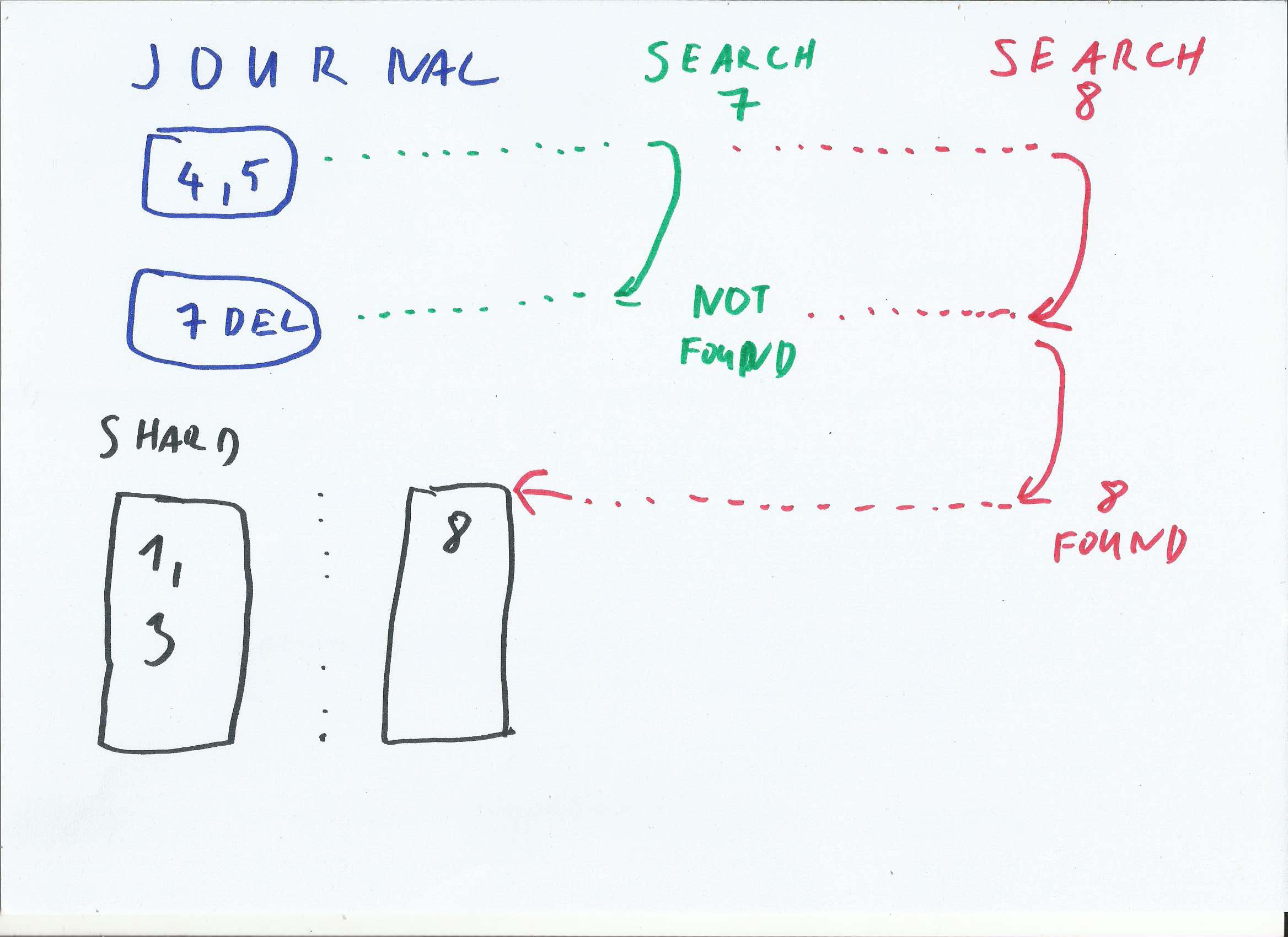 Find key in IODB
Find key in IODB
Image above shows simple IODB store. Journal contains keys 4 and 5, and deleted key 7. There are two shards, with content 1, 3 and 8.
First is search for key 7 (in green). Tombstone (delete marker) is found in Journal, so key-search returns ‘not found’
Second search is for key 8 (in red). Journal is traversed without finding a key. In next step shard with given interval is selected. Key 8 is found within shard.